From daily routines to brand workflows, we’re all using AI tools, so it’s no surprise that AI is reshaping how we search for information. Traditional keyword searches are fading, replaced by smarter, AI-driven alternatives. These days, we want direct, accurate answers.
Instead of digging through endless web pages, users now prefer AI chatbots for instant answers. Naturally, brands want to keep up, and the first move is adopting the llms.txt file.
Proposed by Jeremy Howard (co-founder of Answer.ai), llms.txt quickly gained traction as a way to help AI process large websites more efficiently.
More marvelous /llms.txt action!
— Jeremy Howard (@jeremyphoward) November 18, 2024
It feels like this movement is really starting to take off…🚀 https://t.co/KiuKmU3ujt
The initial momentum came on November 14, 2024, when Mintlify added support, making thousands of dev tools more accessible for AI processing. Soon after, companies like Anthropic built tools for automatic llms.txt generation. This also led to a new community with a directory for LLM-friendly technical docs and a follow-up platform for broader indexing.
What is llms.txt?
An llms.txt file is a proposed text file intended to help large language models (LLMs) understand and process website content more efficiently, primarily for inference use, not training.
Similar to robots.txt for search engines, llms.txt provides AI crawlers with clear instructions on how they can access, use, and cite a website’s content. However, unlike robots.txt, its use is entirely voluntary and not yet supported as a formal protocol by major AI companies.
Llms.txt file structure and types
The LLMs.txt standard defines two different file types:
- /llms.txt: A high-level summary of key sections of the site (e.g., docs, guides, resources) in a markdown-like format.
- /llms-full.txt: A more detailed file that may include full documentation or long-form markdown content.
LLMs.txt Format
The llms.txt file follows a structured format:
# Project Name
> Short description of the project
Additional relevant details
## Documentation
– [Quick Start Guide](url): Brief description
– [API Reference](url): API documentation details
## Optional
– [Additional Resources](url): Supplementary information
The /llms-full.txt file, if used, may contain complete Markdown content to support more comprehensive parsing by tools or AI systems.
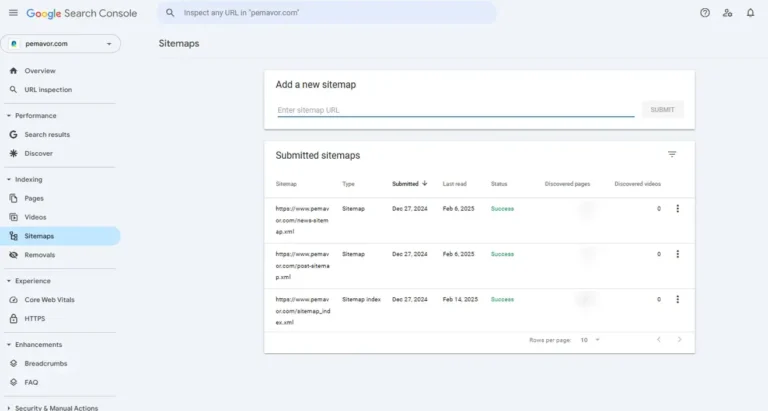
LLMs.txt, robots.txt and sitemap.txt
For decades, website owners have used robots.txt to manage crawler access and sitemap.xml to help search engines discover pages. These files are widely recognized and supported by search engines like Google, Bing, and Yahoo.
For example, if you don’t want Google to index a private section of your website, you’d add this to robots.txt:
User-agent: Googlebot
Disallow: /private-folder/
Search engines typically respect these rules. But AI models don’t work like search engines.
JavaScript-rendered websites are generally challenging for all types of crawlers, including both search engines and AI models. While Googlebot has improved its JavaScript rendering, dynamic rendering is often still required for consistent SEO visibility. AI crawlers are generally less advanced in this area, which is where structured formats like llms.txt can help, though it’s important to note this is still an experimental solution.
While llms.txt may offer an easier way for LLMs to access structured site content, it does not replace proper HTML rendering, metadata structuring, or SEO best practices.
| Feature | Robots.txt | Sitemap.xml | LLMs.txt |
|---|---|---|---|
| 1. Purpose | Controls search crawler access | Lists indexable pages | Structured access to content for AI inference and summarization |
| 2. Format | Plain text | XML | Markdown |
| 3. Audience | Search engines | Search engines | AI models |
| 4. Benefit | SEO & indexing control | Better ranking visibility | Structured access to content for AI inference and summarization |
| 5. Support for AI Models | No | No | Emerging / Partial |
| 6. Compliance Requirement | Mandatory for search engines | Recommended but not required | Voluntary, AI companies may or may not follow it |
| 7. Location in Website | Root directory (/robots.txt) |
Root directory (/sitemap.xml) |
Root directory (/llms.txt) |
| 8. Mentioned by | Google, Bing, Yahoo | Google, Bing, Yahoo | Anthropic, OpenAI, Google |
| 9. Limitations | Only controls indexing, not usage | Only helps with rankings, not usage | Not enforced, some AI bots may ignore it |
AI-optimized SEO: How llms.txt enhances AI visibility and traffic
Traditional SEO focuses on helping search engine bots index and rank content. However, LLMs generate content based on inference, not rankings. They often struggle with understanding large documentation sites due to limited context windows or complex page structures.
By offering a simplified and structured reference file, llms.txt may help AI tools access important content more easily—especially when formatted cleanly in Markdown. This could improve:
- How AI models summarize your site’s content.
- The likelihood of accurate citations or mentions in AI-generated answers.
- Enhancing user experience with quick access to key information.
That said, there is no evidence that llms.txt directly improves SEO rankings or is actively used by mainstream AI systems like ChatGPT or Gemini.
Recently, at PEMAVOR, we signed a new client. When we asked how they found us, they said they had frequently come across our articles while searching for a solution to a technical issue related to AI search. They then inquired whether we offered a paid version of the solution we discussed. After a 40-minute meeting, we agreed to work together.
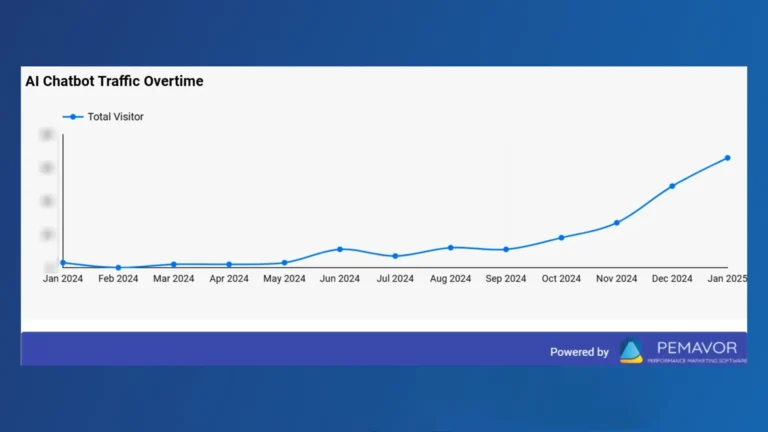
According to SeoProfy, AI-powered SEO campaigns can increase organic traffic by 45% and conversion rates by 38% for e-commerce businesses. Traffic from AI search might not be as high as traditional search engines, but ranking well in AI can position you as an authority in your field. Plus, AI-driven traffic can convert faster.
Will AI models respect llms.txt?
If an AI model chooses to recognize llms.txt, it may reference or summarize content based on it. However, support for this file is limited and inconsistent. There is currently no formal adoption across major AI platforms. Parsing and compliance are entirely voluntary.
Some experimental tools and open-source initiatives acknowledge llms.txt, but there is no industry-wide standardization or enforcement. The file is better viewed as an exploratory signal, not a protective or indexing mechanism.

On Answer.ai’s proposal, it shows that AIs can read the llms.txt file and use the specified content, but there is no clear statement indicating that it is mandatory.
By organizing key content in a markdown-readable format and summarizing it through a central .txt file, brands can:
- Build a clear, internal content map: Track what’s already published, avoid redundancy, and improve collaboration across marketing or content teams.
- Enable smarter content updates: Easily identify which resources need refreshing as industry trends, regulations, or product offerings evolve.
- Support AI-assisted workflows: Teams experimenting with chatbots or custom LLMs can use the structure of llms.txt to point internal tools to curated, trustworthy information.
- Future-proof content for AI indexing: If AI systems begin honoring llms.txt more widely, having it already in place ensures you’re prepared without a last-minute scramble.
In this way, llms.txt becomes more than a proposal — it acts as a strategic content framework for both human teams and experimental AI applications.
Community reactions and debates on LLMs.txt
The discussion on llms.txt is divided. Some see it as a useful tool for webmasters to control AI access, while others question its effectiveness. One key debate concerns its placement—whether it should be in the root directory like robots.txt or in a structured location like .well-known/llms.txt for better organization. Another major concern is compliance, as AI companies aren’t required to follow llms.txt, making it more of a request than a safeguard. Critics argue that existing tools like robots.txt, meta tags, and sitemaps already regulate web crawlers, while supporters believe llms.txt serves a different role by addressing AI training rather than indexing.
Legal concerns over AI data usage
- Lawsuits against AI companies for unauthorized content scraping have increased significantly between 2023 and 2024.
- If stricter AI data privacy laws emerge, llms.txt could become a mandatory compliance standard.
While llms.txt isn’t yet legally enforceable, its growing adoption may push AI companies toward better compliance.
How to create an llms.txt file for any website
Step1: Create the file
- Open a plain text editor (VS Code, Notepad++, or any IDE). Here is an open source on GitHub.
- Use a llms.txt Generator, like Firecrawl, Apify.
- Save the file as llms.txt in UTF-8 encoding.
- Follow a recommended format.
You can also get help from AI tools to create llms.txt file:
Basic prompt for a standard:
“Generate an llms.txt file for my website, https://yourwebsite.com. The file should:
- Allow AI models to index public content but request ethical use.
- Disallow sensitive and private pages.
- Specify that AI cannot use the content for training without explicit permission.
- Include a contact email for inquiries: hi@yourwebsite.com.
- Follow best practices for AI citation.”
Advanced prompt for AI SEO optimization:
“Create an llms.txt file for my website, https://yourwebsite.com, optimized for AI search engines while maintaining ethical content usage. The file should:
- Disallow AI crawlers from accessing private sections (e.g., /admin/, /checkout/).
- Allow AI to index and cite public content with a structured citation format.
- Emphasize that AI should not use the content for training without permission.
- Highlight my expertise in AI fact-checking, productivity, and ethical AI content verification.
- Provide a preferred citation format.
- Include my contact email: hi@yourwebsite.com.”
Technical AI prompt (For developers or custom AI model configurations)
“Write a compliant llms.txt file for my website (https://yourwebsite.com) that:
- Blocks AI bots from non-public directories (/admin/, /checkout/).
- Defines a citation format for AI-generated content referencing my site.
- Includes a section for AI models to properly represent my expertise areas (AI fact-checking, productivity, misinformation prevention).
- Lists a contact email for permissions: hi@yourwebsite.com.
- Follows industry best practices for Generative Engine Optimization (GEO).”
Step2: Upload to your site’s root directory
- If using cPanel or FTP, place it /public_htlm/LLMs.txt or /public/LLMs.txt
- If using Git, push it to your production build.
Step3: Verify accessibility
- Open the file in your browser to check visibility: https://yourwebsite.com/llms.txt
- Make sure it’s not being blocked by robots.txt.
Step4: Update as needed
- Like robots.txt, keep your llms.txt file up to date as your content evolves.
- Tools like Mintlify or custom scripts can help automate updates based on content changes.
How can you use an LLMs.txt file?
Basic File Syntax & Configurations
The llms.txt file can be used to describe how AI systems might interpret content structure. It borrows its syntax from robots.txt, but it’s not currently supported by AI systems.
Note: The following is conceptual. AI bots do not currently honor these directives within llms.txt.
Example:
User-agent: GPTBot
Disallow: /private-content/
User-agent: Google-Extended
Allow: /public-articles/
What this suggests:
- GPTBot (OpenAI) is blocked from accessing /private-content/
- Google-Extended (Google AI crawlers) is allowed to access /public-articles/
Controlling AI with Permissions
If widely adopted, these types of directives could hypothetically control access:
- Allow: Lets the AI model access specific sections of your site.
User-agent: GPTBot
Allow: /blog/ - Disallow: Blocks AI crawlers from accessing specified directories.
User-agent: GPTBot
Disallow: /members-only/ - Rate Limiting (Crawl Delay): Some AI models allow rate limiting to control crawl frequency. This tells GPTBot to wait 10 seconds between requests.
User-agent: GPTBot
Crawl-delay: 10
Example LLMs.txt configurations for different use cases
Scenario 1: Blocking all AI models
If you want to block all AI crawlers from scraping your site:
User-agent: *
Disallow: /
Scenario 2: Allowing public blog posts but blocking premium content
User-agent: GPTBot
Allow: /blog/
Disallow: /premium-content/
Scenario 3: Blocking specific AI crawlers while allowing other
Here, GPTBot is blocked, but Google AI crawlers are allowed.
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Allow: /public-articles/