
We already shared some clustering approaches using TF-IDF Vectorizer for grouping keywords together. This works great for grouping keywords together that share the same text strings, but you aren’t able to group by meaning and semantic relationships.
One way to deal with semantics is building up e.g. word2vec models and cluster keywords with Word Mover’s Distance. The downside: you have to spend some effort building such models. For this reason, we want to show you a more accessible solution you can just download and run.

Use the Google SERP results to discover semantic relationships
Google is using NLP (Natural Language Processing) models to offer the best search results for the user. Yes, it’s a blackbox, but we can use it for our advantage. Instead of building own models, we use this blackbox to group keywords by their semantic. Here is how the program logic works:
- Starting point is a list of keywords for a topic.
- We scrape the SERP (Search Engine Result Page) results for every keyword.
- A graph is created by using the relationship between keywords and ranking pages: If the same pages rank for different keywords, they seem to be related together. This is the principle we’re creating the semantic keyword clusters.
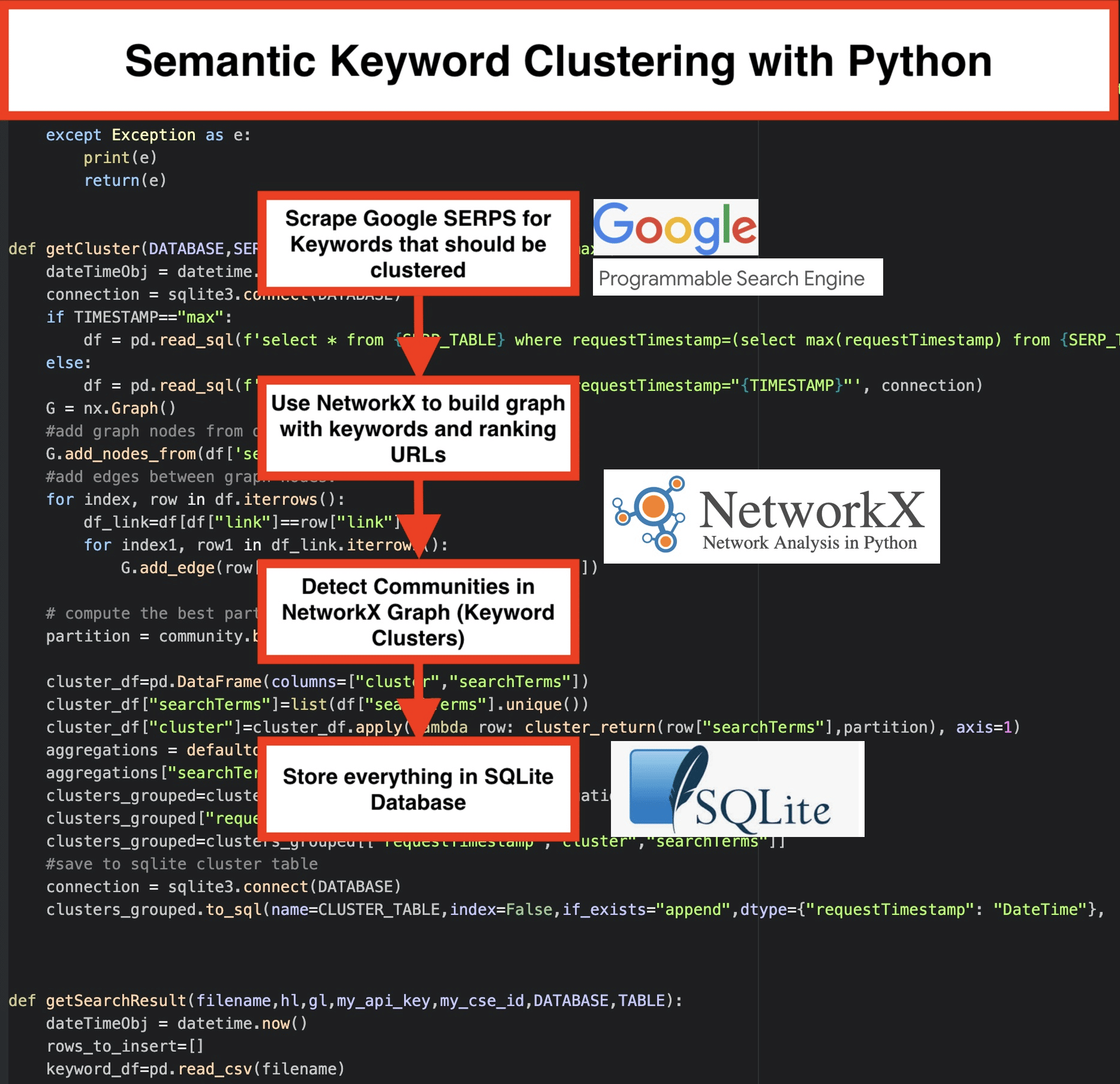
Let’s put everything together in Python
The Python Script covers these functionalities:
- Download the SERPs for a given list of keywords using Google’s custom search engine. The results are saved to a SQLite database. You need to set up a custom search API here. After doing this, you can use the free quota of 100 requests per day—if you have bigger keyword sets and you need results right away, the paid plan will cost you $5 per 1000 requests. If you have time go with the SQLite solutions, the SERP results will be appended to the table on each run (just take a new set of 100 keywords for the next day when the free quota is available again). In the python script, you have to set up this variables:
- CSV_FILE=”keywords.csv” => store your keywords here
- LANGUAGE = “en”
- COUNTRY = “en”
- API_KEY=”xxxxxxx”
- CSE_ID=”xxxxxxx”
Running getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) will write the SERP results to the database
- The Clustering is made using networkx and the community detection module. The data is fetched from the SQLite database—the clustering is called with getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)
- The Clustering results can be found in the SQLite table—if you don’t change the name it is “keyword_clusters” by default.
Here is the full code:
# Semantic Keyword Clustering by Pemavor.com
# Author: Stefan Neefischer (stefan.neefischer@gmail.com)
from googleapiclient.discovery import build
import pandas as pd
import Levenshtein
from datetime import datetime
from fuzzywuzzy import fuzz
from urllib.parse import urlparse
from tld import get_tld
import langid
import json
import pandas as pd
import numpy as np
import networkx as nx
import community
import sqlite3
import math
import io
from collections import defaultdict
def cluster_return(searchTerm,partition):
return partition[searchTerm]
def language_detection(str_lan):
lan=langid.classify(str_lan)
return lan[0]
def extract_domain(url, remove_http=True):
uri = urlparse(url)
if remove_http:
domain_name = f"{uri.netloc}"
else:
domain_name = f"{uri.netloc}://{uri.netloc}"
return domain_name
def extract_mainDomain(url):
res = get_tld(url, as_object=True)
return res.fld
def fuzzy_ratio(str1,str2):
return fuzz.ratio(str1,str2)
def fuzzy_token_set_ratio(str1,str2):
return fuzz.token_set_ratio(str1,str2)
def google_search(search_term, api_key, cse_id,hl,gl, **kwargs):
try:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10, cx=cse_id, **kwargs).execute()
return res
except Exception as e:
print(e)
return(e)
def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs):
try:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10, cx=cse_id, **kwargs).execute()
return res
except Exception as e:
print(e)
return(e)
def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"):
dateTimeObj = datetime.now()
connection = sqlite3.connect(DATABASE)
if TIMESTAMP=="max":
df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', connection)
else:
df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', connection)
G = nx.Graph()
#add graph nodes from dataframe columun
G.add_nodes_from(df['searchTerms'])
#add edges between graph nodes:
for index, row in df.iterrows():
df_link=df[df["link"]==row["link"]]
for index1, row1 in df_link.iterrows():
G.add_edge(row["searchTerms"], row1['searchTerms'])
# compute the best partition for community (clusters)
partition = community.best_partition(G)
cluster_df=pd.DataFrame(columns=["cluster","searchTerms"])
cluster_df["searchTerms"]=list(df["searchTerms"].unique())
cluster_df["cluster"]=cluster_df.apply(lambda row: cluster_return(row["searchTerms"],partition), axis=1)
aggregations = defaultdict()
aggregations["searchTerms"]=' | '.join
clusters_grouped=cluster_df.groupby("cluster").agg(aggregations).reset_index()
clusters_grouped["requestTimestamp"]=dateTimeObj
clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]]
#save to sqlite cluster table
connection = sqlite3.connect(DATABASE)
clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
def getSearchResult(filename,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE):
dateTimeObj = datetime.now()
rows_to_insert=[]
keyword_df=pd.read_csv(filename)
keywords=keyword_df.iloc[:,0].tolist()
for query in keywords:
if hl=="default":
result = google_search_default_language(query, my_api_key, my_cse_id,gl)
else:
result = google_search(query, my_api_key, my_cse_id,hl,gl)
if "items" in result and "queries" in result :
for position in range(0,len(result["items"])):
result["items"][position]["position"]=position+1
result["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"])
result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query)
result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query)
result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query)
result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query)
result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"])
for position in range(0,len(result["items"])):
rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl,
"totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"],
"displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"],
"position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"],
"snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"],
"snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"],
"title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"],
})
df=pd.DataFrame(rows_to_insert)
#save serp results to sqlite database
connection = sqlite3.connect(DATABASE)
df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
##############################################################################################################################################
#Read Me: #
##############################################################################################################################################
#1- You need to setup a google custom search engine. #
# Please Provide the API Key and the SearchId. #
# Also set your country and language where you want to monitor SERP Results. #
# If you don't have an API Key and Search Id yet, #
# you can follow the steps under Prerequisites section in this page https://developers.google.com/custom-search/v1/overview#prerequisites #
# #
#2- You need also to enter database, serp table and cluster table names to be used for saving results. #
# #
#3- enter csv file name or full path that contains keywords that will be used for serp #
# #
#4- For keywords clustering enter the timestamp for serp results that will used for clustering. #
# If you need to cluster last serp results enter "max" for timestamp. #
# or you can enter specific timestamp like "2021-02-18 17:18:05.195321" #
# #
#5- Browse the results through DB browser for Sqlite program #
##############################################################################################################################################
#csv file name that have keywords for serp
CSV_FILE="keywords.csv"
# determine language
LANGUAGE = "en"
#detrmine city
COUNTRY = "en"
#google custom search json api key
API_KEY="ENTER KEY HERE"
#Search engine ID
CSE_ID="ENTER ID HERE"
#sqlite database name
DATABASE="keywords.db"
#table name to save serp results to it
SERP_TABLE="keywords_serps"
# run serp for keywords
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)
#table name that cluster results will save to it.
CLUSTER_TABLE="keyword_clusters"
#Please enter timestamp, if you want to make clusters for specific timestamp
#If you need to make clusters for the last serp result, send it with "max" value
#TIMESTAMP="2021-02-18 17:18:05.195321"
TIMESTAMP="max"
#run keyword clusters according to networks and community algorithms
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)



